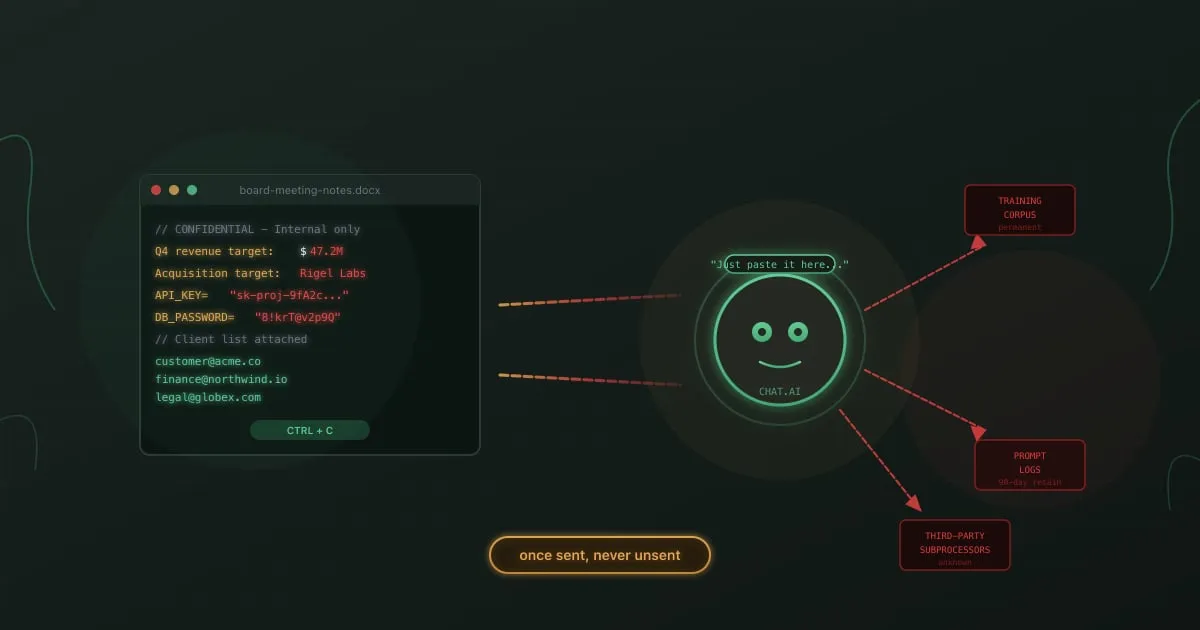
Напівпровідниковий підрозділ Samsung заборонив ChatGPT у травні 2023 року після того, як троє співробітників злили конфіденційні дані менш ніж за місяць. Один інженер вставив пропрієтарний вихідний код, щоб налагодити помилку. Інший надіслав нотатки з внутрішньої наради для генерації конспекту. Третій завантажив виміри виробництва чипів, щоб отримати розрахунок виходу. Кожен із них намагався робити свою роботу швидше. Кожен залишив копію комерційної таємниці Samsung на сервері OpenAI.
За кілька тижнів Apple, JPMorgan, Bank of America, Verizon, Amazon, Goldman Sachs та Deutsche Bank додали свої обмеження. Розрахунок був однаковим у кожній компанії. Продуктивний виграш був реальним, але реальним був і ризик того, що співробітники перетворюють споживчі інструменти ШІ на канал виводу даних, який ніхто не санкціонував.
Через два роки заборони помʼякшилися до політик, а політики помʼякшилися до прогалин у навчанні. Більшість співробітників досі не розуміють, що відбувається з текстом, який вони вставляють у вікно ШІ-чату. Це суть OWASP LLM02 — ризику розкриття чутливої інформації, який посідає друге місце в OWASP Top 10 для LLM-застосунків.