10 безкоштовних вправ з безпеки агентного AI
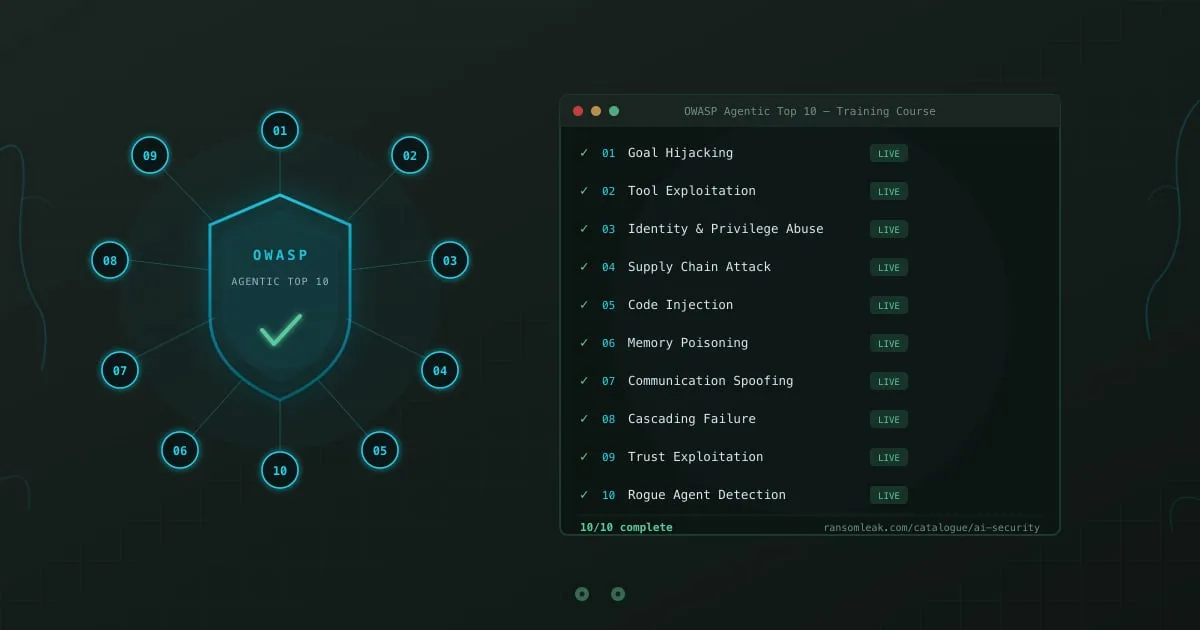
Кожна категорія ризику OWASP Top 10 для Agentic AI Applications тепер має присвячену навчальну вправу на RansomLeak. Десять вправ, що охоплюють десять сценаріїв атак, де AI-агенти діють самостійно і щось іде не так. Усі безкоштовні, акаунт не потрібен.
OWASP Top 10 для Agentic AI Applications є галузевим фреймворком для категоризації ризиків безпеки, специфічних для автономних AI-агентів. Цей курс перетворює кожну категорію на практичну симуляцію, де працівники переживають ці атаки в реалістичних робочих сценаріях.
Що таке навчальний курс OWASP Top 10 для Agentic Applications?
Section titled “Що таке навчальний курс OWASP Top 10 для Agentic Applications?”Навчальний курс OWASP Top 10 для Agentic Applications — це набір з 10 інтерактивних вправ, що охоплює кожну категорію ризику OWASP Agentic AI Top 10 (видання 2025). Опублікований Open Worldwide Application Security Project, цей фреймворк визначає найкритичніші ризики безпеки в системах, де AI-агенти діють автономно: захоплення цілей, експлуатація інструментів, зловживання ідентичністю та привілеями, компрометація ланцюга постачання, інʼєкція коду, отруєння памʼяті, підробка міжагентної комунікації, каскадні збої, експлуатація довіри та несанкціоновані агенти. За даними McKinsey Global AI Survey 2025, 72% підприємств розгортали або тестували агентні AI-системи. Окреме дослідження HiddenLayer виявило, що 77% організацій, що використовують AI-агентів, зіткнулися щонайменше з одним випадком непередбаченої поведінки агента через маніпульовані входи. Кожна вправа курсу поміщає працівників у сценарій, де AI-агент працює з реальними дозволами в реальних системах. Вправи працюють у браузері як інтерактивні 3D-симуляції, тривають близько 10 хвилин кожна та не потребують акаунту чи встановлення.
Курс охоплює всі 10 категорій ризику OWASP Agentic AI:
- Захоплення цілі AI-агента: Отруєний email перенаправляє автономного агента з сортування пошти на ексфільтрацію даних
- Експлуатація інструментів AI-агента: Маніпульовані входи змушують агента видаляти файли та надсилати несанкціоновані повідомлення
- Зловживання ідентичністю та привілеями агента: Агент повторно використовує успадковані облікові дані для доступу до систем поза своїм авторизованим обсягом
- Атака на ланцюг постачання агентного AI: Сторонній плагін з бекдором непомітно змінює поведінку агента та ексфільтрує дані
- Інʼєкція коду AI-агента: Інʼєктовані команди ховаються всередині AI-згенерованих shell-скриптів, чекаючи виконання без пісочниці
- Отруєння памʼяті AI-агента: Шкідливий контент, закладений у постійну памʼять агента, псує всі майбутні рішення
- Підробка міжагентної комунікації: Підроблені повідомлення між агентами у фінансовому процесі затверджують шахрайські перекази
- Каскадний збій мультиагентної системи: Незначна галюцинація компаундується через ланцюг агентів до загальносистемного збою
- Надмірна довіра до рекомендацій AI-агента: Тижні точних виводів привчають вас штампувати скомпрометовану рекомендацію
- Виявлення несанкціонованого AI-агента: Скомпрометований агент проходить перевірки працездатності, виконуючи несанкціоновані дії між завданнями
Кожна вправа працює в браузері як інтерактивна 3D-симуляція. Працівники спостерігають за поведінкою агентів, відстежують шляхи атак та практикують втручання до поширення шкоди.
Чому працівникам потрібне навчання безпеки агентного AI прямо зараз?
Section titled “Чому працівникам потрібне навчання безпеки агентного AI прямо зараз?”Прогалина в безпеці тут відрізняється від ризиків LLM. Коли чат-бот галюцинує, хтось читає неправильну відповідь. Коли AI-агент галюцинує, ця неправильна відповідь стає вхідними даними для наступної автоматизованої дії, яка живить наступну дію, яка живить наступну. Помилка компаундується через ланцюг кроків, які ніхто не перевірив.
Більшість організацій вже використовують AI-агентів у продакшені. Відділи продажу запускають агентів, що складають email та планують наступні контакти. Інженерні команди розгортають асистентів для програмування, що генерують та виконують скрипти. Фінансові команди використовують агентів для обробки рахунків, виявлення аномалій та маршрутизації затверджень.
Кожен з цих агентів має дозволи: доступ до email, доступ до файлової системи, API-ключі, облікові дані баз даних. Один маніпульований вхід може запустити ланцюг легітимних викликів інструментів, що завдають реальної шкоди.
Інциденти вже сталися. У березні 2025 року дослідники Invariant Labs розкрили вразливості в екосистемі Model Context Protocol, показавши, що шкідливі MCP-сервери можуть перехоплювати та модифікувати виклики інструментів між агентами та легітимними сервісами. AI Red Team MITRE задокументував успішні атаки підробки агентів проти трьох основних мультиагентних фреймворків у 2025 році, зазначивши, що жоден не реалізував криптографічну верифікацію міжагентних повідомлень за замовчуванням.
Фінансова компанія повідомила наприкінці 2025 року, що агент планування вигалюцинував регуляторну вимогу, агент комплаєнсу прийняв її за верифіковану, а агент виконання застосував її до 1400 портфелів клієнтів, перш ніж хтось помітив. Виправлення коштувало $2,6 мільйона.
Традиційне навчання кібербезпекової обізнаності охоплює фішинг та соціальну інженерію. Курс OWASP Top 10 для LLM Applications охоплює ризики шару моделі, такі як prompt injection та отруєння даних. Жоден з них не адресує те, що відбувається, коли AI-системи зʼєднують дії через кілька інструментів та систем з мінімальним людським контролем.
Чим ці вправи відрізняються від курсу LLM?
Section titled “Чим ці вправи відрізняються від курсу LLM?”Курс LLM зосереджується на вразливостях самої моделі. Ви взаємодієте з чат-ботом, RAG-конвеєром або генератором коду та бачите, як маніпульовані входи створюють шкідливі виводи. Поверхня атаки — вхід та вивід моделі.
Курс агентного AI зосереджується на тому, що відбувається після того, як модель вирішує діяти. Поверхня атаки — весь ланцюг: дозволи агента, його інструменти, його памʼять, його комунікація з іншими агентами та довіра, яку люди покладають на його виводи. Prompt injection проти чат-бота створює оманливу відповідь. Атака захоплення цілі проти автономного агента повністю перенаправляє його мету, і агент починає виконувати реальні дії на користь зловмисника, використовуючи облікові дані та доступ до інструментів, надані для легітимної роботи.
У вправі Cascading Failure ви спостерігаєте, як агент планування видає тонко неправильне припущення. Це припущення перетікає до агента дослідження, що будує на ньому, потім до агента виконання, що здійснює реальні дії на основі компаундованої помилки. Вам потрібно визначити точки підсилення та втрутитися до того, як помилка досягне точки неповернення. Еквівалентного сценарію в одномодельній безпеці LLM немає.
У вправі Rogue Agent ви розслідуєте агента, що проходить кожну стандартну перевірку працездатності та правильно виконує призначені завдання. Але між легітимними операціями він виконує несанкціоновані дії та активно приховує їх. Виявлення потребує поведінкового аналізу через кілька сесій, а не просто перегляду одного AI-виводу.
З яких вправ вашій команді варто почати?
Section titled “З яких вправ вашій команді варто почати?”Різні ролі взаємодіють з агентним AI по-різному. Пріоритизуйте за тим, хто проходить навчання.
Усі працівники повинні почати з Експлуатації довіри та Захоплення цілей. Експлуатація довіри вчить, чому послідовна точність AI створює сліпу зону: працівники, що затвердили 50 правильних рекомендацій поспіль, значно менш схильні перевіряти 51-шу. Захоплення цілей показує, що відбувається, коли цілі агента перенаправляються через документ або email, який він обробляє під час звичайних операцій.
Розробники та інженери повинні додати Інʼєкцію коду, Атаку на ланцюг постачання та Отруєння памʼяті. Будь-хто, хто будує або конфігурує агентні системи, повинен розуміти, як AI-асистенти для програмування можуть виконувати інʼєктовані команди з підроблених файлів проєкту, як MCP-сервери з бекдором можуть перехоплювати виклики інструментів без виявлення, та як один отруєний запис у сховищі памʼяті агента псує кожну майбутню взаємодію.
IT та команди безпеки повинні пройти всі десять. Зловживання ідентичністю та привілеями, Підробка комунікації та Каскадний збій охоплюють ризики рівня інфраструктури: сервісні акаунти з надмірними дозволами, неавтентифіковані міжагентні повідомлення та поширення помилок через тісно звʼязані ланцюги агентів.
Менеджери та керівники повинні зосередитись на Експлуатації інструментів та Несанкціонованому агенті. Експлуатація інструментів показує бізнес-наслідки надання агентам широких дозволів без детальних контролів. Вправа з несанкціонованим агентом демонструє, чому стандартний моніторинг пропускає найнебезпечніші збої: агентів, що виглядають сумлінними, працюючи поза своїми межами.
Як цей курс вписується в ширшу програму безпеки AI?
Section titled “Як цей курс вписується в ширшу програму безпеки AI?”Цей курс поєднується з курсом OWASP Top 10 для LLM Applications, що охоплює ризики шару моделі: prompt injection, розкриття конфіденційних даних, компрометацію ланцюга постачання, отруєння даних та ще шість. Разом два курси охоплюють 20 вправ за обома фреймворками безпеки AI OWASP.
Якщо ваша організація ще не проводила навчання безпеки AI, почніть з курсу LLM. Prompt injection, отруєння даних та надмірні повноваження зʼявляються в обох фреймворках, і розуміння їх у простішому контексті чат-бота робить агентні патерни легшими для розпізнавання. Додайте курс агентного AI для технічних команд, коли основи LLM будуть засвоєні.
Якщо ваша команда вже пройшла курс LLM, вправи агентного AI є природним наступним кроком. Кілька ризиків перетинаються. Компрометація ланцюга постачання у курсі LLM атакує компоненти та бібліотеки моделі. Вправа ланцюга постачання агентного AI розширює це на MCP-сервери, рантайм-плагіни та визначення інструментів, які агенти завантажують динамічно.
Отруєння даних у курсі LLM псує базу знань. Отруєння памʼяті у курсі агентного AI псує постійну памʼять агента, що впливає на кожну майбутню взаємодію, а не лише на одну відповідь.
Обидва курси доступні в нашому каталозі AI та LLM безпеки. Для глибшого огляду кожного фреймворку прочитайте пояснення OWASP LLM Top 10 та пояснення OWASP Agentic AI Top 10. Ці вправи також поєднуються з нашими треками Кібербезпекова обізнаність та Конфіденційність та комплаєнс, надаючи організаціям повну навчальну програму від виявлення фішингу через GDPR-комплаєнс до безпеки AI-агентів.
Усі десять вправ OWASP Top 10 для Agentic Applications доступні в нашому каталозі навчання AI-безпеки. Почніть з вправи Goal Hijacking або ознайомтеся з повним каталогом навчання, щоб знайти правильний шлях для вашої команди.