AI Data Leakage
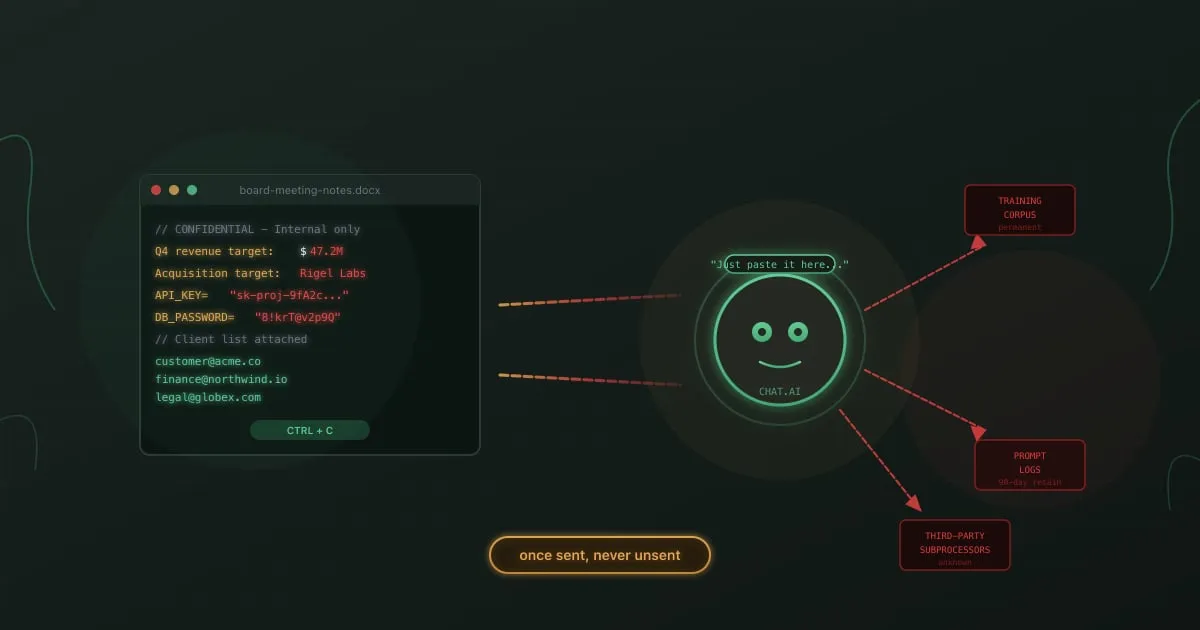
Samsung’s semiconductor division banned ChatGPT in May 2023 after three employees leaked confidential data in under a month. One engineer pasted proprietary source code to debug an error. Another submitted internal meeting notes to generate a summary. A third uploaded chip manufacturing measurements to get yield calculations. Each person was trying to do their job faster. Each left a copy of Samsung’s trade secrets on an OpenAI server.
Within weeks, Apple, JPMorgan, Bank of America, Verizon, Amazon, Goldman Sachs, and Deutsche Bank had followed with their own restrictions. The calculus was the same at every company. The productivity gains were real, but so was the risk of employees turning consumer AI tools into a data exfiltration channel nobody had authorized.
Two years later, the bans have softened into policies, and the policies have softened into training gaps. Most employees still don’t understand what happens to the text they paste into an AI chat window. This is the core of OWASP LLM02, the sensitive information disclosure risk that sits second on the OWASP Top 10 for LLM Applications.
What is AI data leakage?
Section titled “What is AI data leakage?”AI data leakage is the exposure of confidential, regulated, or proprietary information to large language model systems through employee interactions. It happens when workers paste sensitive content into consumer AI chatbots, share files with AI-enabled productivity tools, or connect internal systems to third-party AI services without adequate controls.
The leaked data can persist in prompt logs, vector databases, model memory, or future training datasets depending on the vendor’s retention policy. A 2023 Cyberhaven analysis of activity from 1.6 million knowledge workers found that 11% of the content employees pasted into ChatGPT was confidential, including source code, client data, and regulated information.
Unlike traditional data breaches, AI leakage rarely triggers alerts because the traffic flows over encrypted HTTPS to legitimate domains. The data leaves the organization quietly, one prompt at a time, through tools employees believe are helping them work faster.
How does data leak into LLMs in the first place?
Section titled “How does data leak into LLMs in the first place?”Employee leakage happens through four separate channels. Each one needs a different control.
Direct prompt pasting. This is the Samsung pattern. An employee copies code, contracts, customer records, board minutes, or strategic plans into a chat window. The text travels to the vendor’s servers, gets processed for inference, and stays in request logs. On consumer tiers, it may also enter training data queues.
Training data memorization. Models can memorize specific text from their training sets and reproduce it verbatim when prompted correctly. Google DeepMind researchers demonstrated in 2023 that GPT-3.5 could be coaxed into regurgitating email addresses, phone numbers, and passages from copyrighted books through simple repetition attacks. If your proprietary content ever enters a training pipeline, fragments may surface later in someone else’s conversation.
AI-enabled application connections. Copilot, Gemini, and similar tools index email, documents, and chat history to make their suggestions useful. A misconfigured Copilot deployment can expose documents an employee shouldn’t have access to by surfacing them in search results. Microsoft has publicly acknowledged oversharing as one of the top Copilot rollout risks.
Third-party integrations and browser extensions. AI writing assistants, meeting recorders, and productivity plugins process the content they see. Each one creates a new data flow to a new vendor, often governed by a terms-of-service the employee clicked through in twenty seconds.
The Sensitive Data Disclosure exercise puts employees through all four scenarios in a single 15-minute simulation.
Why did Samsung actually ban ChatGPT?
Section titled “Why did Samsung actually ban ChatGPT?”The Samsung incidents got more attention than any other early AI data leakage case, and the specifics are worth knowing because they show how normal the leakage behavior looked.
In one case, a semiconductor engineer wanted to check his own source code for errors. He pasted it into ChatGPT with a prompt asking for optimizations. The code was part of a confidential chip design project. In another, an employee submitted a recording of an internal meeting to get a transcription and summary. The meeting contained strategic details that hadn’t been shared outside the room. A third employee used the tool to generate a presentation from internal yield data.
None of these employees were trying to cause harm. None of them stole data. They used a popular productivity tool the same way they’d use Grammarly or Google Translate, without realizing that OpenAI’s consumer product retained their inputs for training purposes at the time. The leakage happened at the moment of the paste, not at some later breach.
Samsung’s response was immediate. The company issued a written notice, banned generative AI on company devices and networks, and announced plans to build an internal alternative. Violation of the policy was made grounds for termination.
The broader lesson: if a company with Samsung’s security maturity needed less than a month to accumulate multiple incidents, the average enterprise is running a similar risk without knowing it.
What kinds of data leak most often?
Section titled “What kinds of data leak most often?”The Cyberhaven report and subsequent studies from Harmonic, Menlo Security, and Netskope converged on similar categories. Employee AI data leakage tends to concentrate in six buckets.
Source code and technical configuration leak frequently because developers use AI to debug, refactor, and explain unfamiliar code. The leaked snippets often include API keys, database credentials, and internal service names. This overlaps with the broader pattern described in our post on AI coding assistant security risks.
Customer data leaves through support agents drafting responses, sales teams summarizing calls, and marketing teams generating outreach. Names, email addresses, account numbers, and case histories travel to the AI vendor along with the prompt.
Financial data shows up when employees ask AI to reformat spreadsheets, explain variances, or draft investor updates. Revenue figures, forecasts, and deal pipelines end up in logs.
Legal documents and contracts are pasted for summarization, clause comparison, or plain-language translation. This often includes NDAs, which means the act of pasting may itself breach a confidentiality agreement.
Human resources data leaks through performance review drafting, severance communications, and candidate assessment. Health information, compensation details, and disciplinary records flow out with the prompt.
Strategic content, including board materials, product roadmaps, and acquisition plans, leaks when executives and their staff use AI to polish presentations or extract talking points.
Why doesn’t traditional DLP catch this?
Section titled “Why doesn’t traditional DLP catch this?”Traditional Data Loss Prevention tools were built for a threat model that predates ChatGPT. They watch email attachments, USB transfers, personal cloud uploads, and unusual file movements. They struggle with AI interactions for structural reasons.
The traffic looks legitimate. A POST request to api.openai.com or chat.openai.com is encrypted HTTPS going to a well-known business domain. Unless you’re doing SSL inspection with a custom root certificate installed on every endpoint, the DLP engine sees encrypted blobs moving to an allowed destination.
The content isn’t a file. DLP engines are tuned to detect file exfiltration: PDFs leaving the network, spreadsheets being uploaded. A snippet of text pasted into a chat window doesn’t trigger file-based controls because no file was ever created.
The destination keeps changing. ChatGPT was the first target, but employees now use Claude, Gemini, Perplexity, Copilot, Cursor, and dozens of smaller tools. Blocking one domain just pushes usage to the next. Shadow AI follows the same adoption curve we covered in our post on shadow IT security risks, except it moves faster and leaves fewer traces for traditional discovery tools.
The risk is behavioral, not technical. Even if you block every AI domain at the network level, employees will use personal devices, phone browsers, or SSH tunnels to reach the tools they find useful. The training gap has to close alongside the technical one.
Does OpenAI, Anthropic, or Microsoft train on your prompts?
Section titled “Does OpenAI, Anthropic, or Microsoft train on your prompts?”This is the single most confused question in AI data policy, and the answer depends on which product tier you’re using.
For consumer tiers, the default used to be training on user inputs unless the user opted out. OpenAI changed this default for ChatGPT in April 2023 after the Samsung news cycle. Anthropic’s consumer Claude also allows opt-out. Google Gemini offers similar controls. Users who never touched the settings may still have content in training queues from their earlier sessions. Our deeper walkthrough of ChatGPT security risks covers the retention defaults across each tier and the controls that actually change what gets logged.
For business and enterprise tiers, the default is no training. OpenAI’s ChatGPT Enterprise, Anthropic’s Claude for Work, Microsoft Copilot with Commercial Data Protection, and Google Workspace’s Gemini all contractually commit to not using customer inputs for model training. Data still gets logged for abuse monitoring, but it doesn’t enter training pipelines.
For API access, most vendors exclude API data from training by default. This is where the distinction matters most for compliance: API integrations your company builds are different from the consumer app your employees download.
The practical implication: what tier your employees use changes whether pasted data becomes a permanent part of someone else’s model. Most employees have no idea which tier they’re on.
What controls actually reduce AI data leakage?
Section titled “What controls actually reduce AI data leakage?”Effective programs combine four layers. Skipping any one of them leaves an obvious gap.
Contract-level controls mean purchasing enterprise AI tiers with data processing agreements that prohibit training use, limit retention, and document sub-processors. This is the foundation. Consumer tiers leave your data subject to whichever terms the vendor last updated.
Technical controls include AI-aware DLP products, browser extensions that intercept pastes to unauthorized AI domains, and SSO-enforced access that channels all AI usage through managed tenants. Microsoft Purview, Cyberhaven, and Netskope now offer AI-specific DLP modules, but none of them replace policy and training.
Classification controls rely on employees being able to recognize what data they’re about to share. The Data Classification Basics exercise covers the recognition skill directly. Without classification literacy, technical controls devolve into allow-or-block decisions that employees circumvent when the tool stops being useful.
Training controls build the judgment that closes the last gap. Every policy has edge cases. Every technical control has blind spots. Employees who understand what happens to the text they paste make better decisions in the moments the policy doesn’t cover explicitly.
The four layers reinforce each other. Contracts set the vendor-side defaults. Technical controls catch careless pastes. Classification helps employees see what they’re holding. Training turns the first three into habit.
How should employees be trained on AI data leakage risks?
Section titled “How should employees be trained on AI data leakage risks?”Reading a policy doesn’t change behavior. Neither does a video explaining that ChatGPT is risky. What works is letting employees make the mistake in a safe environment and see the consequences play out.
RansomLeak’s AI security training catalogue covers the full OWASP LLM Top 10, but three exercises map most directly to the data leakage problem.
The Sensitive Data Disclosure exercise puts employees in the Samsung scenario. They receive a plausible business task, access a simulated AI assistant, and see what happens when they paste different kinds of content. The debrief shows where the data went, how long it would be retained, and what the classification policy required.
The System Prompt Leakage exercise covers the adjacent risk of prompt extraction, which matters for any organization building internal AI products. Leaked system prompts often contain embedded credentials, API endpoints, and business logic the company considers confidential.
The Accidental Insider Threat exercise addresses the broader human pattern: well-intentioned employees causing harm through convenience shortcuts. AI leakage is one instance of a pattern that also shows up in misaddressed emails, overshared cloud folders, and printed documents left in public spaces.
Role-specific paths help. Engineers need deeper coverage of code leakage and API key exposure. Customer-facing teams need practice with PII in support workflows. Executives need scenarios involving board materials and unannounced strategic content. One-size-fits-all training teaches the policy but doesn’t build the specific judgment each role needs.
Frequency matters too. The vendors change their defaults every few months. New AI features appear inside tools employees already use. A one-time training in 2025 doesn’t cover the Copilot features that shipped in 2026. Short refreshers tied to tooling changes keep the training relevant.
Questions enterprise teams keep asking
Section titled “Questions enterprise teams keep asking”Can I just block ChatGPT at the firewall?
You can, and many enterprises did in the first year after ChatGPT launched. Most eventually softened the block because employees switched to personal devices, phone browsers, or smaller AI tools the firewall hadn’t heard of yet. Network blocks work as a temporary measure while you build the contract and training layers. They don’t work as a strategy.
If we use ChatGPT Enterprise, is the problem solved?
Enterprise tiers eliminate the training-data leakage channel for that specific product. They don’t prevent employees from using personal ChatGPT accounts, from connecting unauthorized AI browser extensions, or from pasting data into whatever new AI tool launched last week. The enterprise contract is one layer, not the whole program.
How is AI data leakage different from general data loss prevention?
Traditional DLP was built around file movements and known exfiltration patterns. AI leakage happens through copy-paste into encrypted web sessions with legitimate vendors, at the speed of a keyboard shortcut. The control architecture needs to be different, and the training content needs to cover risks that didn’t exist when most DLP programs were designed.
Is AI data leakage a GDPR issue?
Yes. Personal data pasted into an AI tool is a processing event under GDPR. The AI vendor becomes a processor. If the legal basis isn’t documented, the processing agreement isn’t in place, or the international transfer isn’t covered, the company has a compliance problem in addition to the security problem. The GDPR data breach response exercise covers the notification timeline when leakage rises to the breach threshold.
Should we be training on this or just block it?
You need both. Blocking without training creates workarounds. Training without blocking creates inconsistent enforcement. The combination of enterprise contracts, paste-aware DLP, classification literacy, and scenario-based exercises produces the behavior change that either control alone cannot.
RansomLeak covers the full OWASP Top 10 for LLM Applications through 10 interactive exercises. Start with the Sensitive Data Disclosure scenario, build the sanitize-first habit with Safe GenAI Usage, or close adjacent data-leakage paths with Log Sensitivity Awareness and Metadata Awareness. Browse the complete AI security training catalogue for more.
Sources
Section titled “Sources”- OWASP Top 10 for LLM Applications 2025
- Bloomberg: Samsung Bans Staff’s AI Use After Spotting ChatGPT Data Leak
- Cyberhaven: How Employees Are Using ChatGPT at Work
- Reuters: Apple Restricts Use of ChatGPT, Joining Other Companies Wary of Leaks
- Google DeepMind: Scalable Extraction of Training Data from Language Models
- Microsoft: Data, Privacy, and Security for Microsoft Copilot
- OpenAI: Enterprise Privacy